Bord 4 til folket!
Journalisten tok en tur til Bergen for å treffe Bord4. Resultatet kan du lese i reportasjen Digitale Vinnere.
Journalisten tok en tur til Bergen for å treffe Bord4. Resultatet kan du lese i reportasjen Digitale Vinnere.
Google maps har mer under panseret enn du kanskje vet om. Trykker du på lenken Map Labs (du må være pålogget en Google konto) får du muligheten til å aktivere flere verktøy. Lenken er godt gjemt nede i det venstre hjørnet.
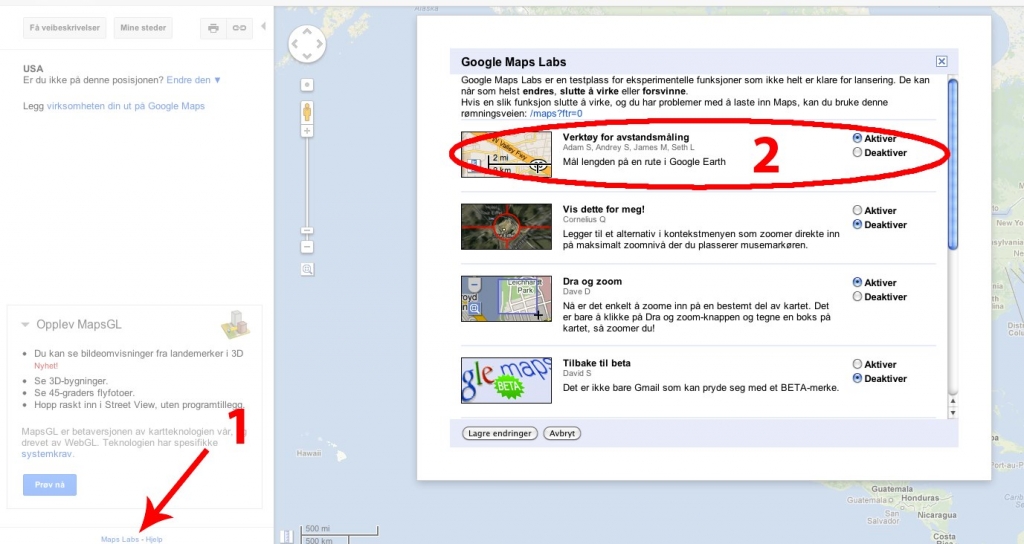
AKTIVER AVSTANDSMÅLING: 1: Trykk på Maps Labs lenken. 2: Aktiver verktøyet.

Bergens Tidende fikk SKUP-diplom for serien «Spillet om klimakronene»
FOTO: SHIFT+CMD+4
Prisutdelingen under årets konferanse ble en serdeles hyggelig opplevelse for Bergens Tidende. Serien «Spillet om klimakronene» ble belønnet med både SKUP-diplom og IR-prisen.
Liste over datajournalistikk og multimediaprosjekt fra BT i året som gikk:
Lenkefest fra Hauststormen: En oversikt over verktøy og inspirasjon om datajournalistikk.
Flere og flere leser historiene våre på mobil og nettbrett. Vi må sørge for at budskapet til historiene våre ikke endrer seg etter hvilken enhet man ser visualiseringen på.
Miranda Mulligan og Pete Karl II gikk gjennom hvordan mobiltelefoner endrer måten vi må tenke på visualiseringer på. De to sentrale begrepene i design for mobil er «Mobile first» og responsivt design. Sistnevnte betyr at man lager en nettside som endrer seg etter hvilken type enhet man ser den med.
Responsivt design er veldig omdiskutert, noe Brad Frost adresserer i artikkelen: Responsive Web Design: Missing the Point
TIl nå har de fleste av oss laget visualiseringer for desktop uten tanke på hvordan utviklingen vil bli. Mulligan manet forsamlingen til å tenke mer langsiktig og sørge for at visualiseringene og historiene våre kan ha evig liv.
Wilson Miner – When We Build from Build on Vimeo.
Jeff Larson og Chase Davis viste praktisk bruke av maskinlæring i journalistikk.
Jeff Larson fra ProPublica gikk gjennom hvordan de brukte maskinlæring på prosjektet The message machine.: «Political campaigns send many variations of each email to supporters. We’ve been collecting emails from political campaigns and tracking the variations.»
Rundt 700 mennesker bidro med 40 000 eposter som de hadde fått tilsendt fra de to leirene. Disse 700 hadde også oppgitt demografisk informasjon om seg selv. Målet var å kunne analysere hvilke type eposter som ble sendt til hvilke gruppering av mennesker.
For å kartlegge variasjonene i språket i de ulike epostene ble de benyttet Document Clustering. For enkle prosjekter har Larson benyttet MinHash-algorimten (funnet opp av Altavista i sin tid) og sitt egenproduserte kommandolinjeverktøy Fast cluster. I «The Message Machine» har han derimot gått for Term Frequency – Inverse-Document Frequency (TD-IDF, grundig gjennomgang finner du her)og Cosine Similarity (fantastisk godt forklart på Stack Overflow).
Etter å ha samlet dokumentene i fornuftige grupper var målet å se hvilke grupper av dokumenter som ble sendt til hvilke type mennesker. For å komme til bunns i dette valgte Larson å bruke en maskinlæringsmetode kalt decision tree, eller beslutningstre på norsk. Decision tree er en av de enkleste algorimtene innenfor maskinlæring. Algorimten blir servert et testsett og prøver å finne regler utfra hva den blir servert. En fordel med Decistion Tree er at det som kommer ut er enkelt å tolke for mennesker.
Weka er et verkøty hvor man kan leke seg med ulike maskinlæringsalgorimter.
Les bloggposten How ProPublica’s Message Machine Reverse Engineers Political Microtargeting for en grundigere gjennomgang
Til slutt kom vår venn Chase Davis inn igjen og gikk gjennom to av sine prosjekter: Fec-standardization og Citizen quote. Han gikk også gjennom mange av konseptene fra sin tidligere seanse.
Ikke bidra til mer datasløsing, Chase Davis oppfordrer journalister til å få empati for dataene sine og å lære seg R.
Den vanlige måten å behandle data på er å forhøre de. Man bør heller utforske dataene og la de fortelle deg hva de egentlig har å si. For å dra det over i journalistbegrep bør man gå fra lukkede spørmål til åpne spørsmål. Man må studere hvordan de ulike variablene oppfører seg og hvordan de på virker hverandre. Hvor er utliggerne? Hva er trendene? Finnes det korrelasjon og medfører det kasualitet? (Forsiktig så du ikke begår en klassisk tankefeil her)
En annen grunn til å utforske dataene nøye er å ikke bidra . Vi sender forespørsler om datasett til det offentlige, får de i hus, publiserer saken og glemmer de. Dette er å kaste bort offentlige ansattes tid og skattepenger. Vi må ta vare på dataene og gjenrbuke de.
Firestegsmodellen
Davis presenterte en firestegsmodell til behandling av data.
For å utføre disse stegene anbefaler Davis at vi kommer oss i gang med R så fort så mulig. På github har han lagt ut et R-skript som viser de ulike stegene. Det er ingen tvil i at dette er et kraftig verktøy det er verdt å bruke tid på å beherske.
Kommandoen sum gir deg et lett overblikk over maks, min, mean og median for feltene dine . R hjelper deg også til å gjøre enkle visualiseringer til å forstå dataene dine bedre. Et scatter plot hjelper deg å finne utliggere, datapunkter som skiller seg ut fra resten. Hva skyldes det? Er det åpenbare årsaker (størrelse i forhold til andre) eller er det et skup?
R hjelper oss også å se på hvordan variablene oppfører seg i forhold til hverandre. Principal Component Analysis og Multi Dimensional Scaling er to metoder for å dypdykke i dataene.